2023年にした浪費
2023年は新しい可能性を求めてこれまでとは違ったお金の使い方を模索していた。 具体的にはPC関連機器以外の使い道を探していた。
Tier1
引越し
同じ場所に住むのも飽きたな、くらいの動機で引越ししたが、結果としてかなりよかった。通勤時間を変えたくなかったので地理的にはさほど変化はないが、それでもいくつかの変化があった。
- 部屋が広くなったので、物を置く余裕が増えた
- 1F -> 2Fに引っ越したので部屋が明るくなった気がする。*1
- 隣がスーパーだったので買い物が楽になった

想定よりも安く借りれたので、余った予算で掃除代行サービスも頼むようにした。知らない人が家入るのに抵抗があったが、慣れれば快適。「人が来るから部屋を片付けなきゃ」という意識が働くのも大きい。

ホテルディナー
日本帰国時にホテルで宿泊しつつ夕食を食べるのを数回やった。
自分は食べログ等のレビューサイトからいい店を探すのが苦手なので、一定の品質が担保されているホテルのレストランは安心感がある。フロントで頼めば当日でも予約が取れる(ことがある)のも便利でいい。

食後、すぐ寝れるのも最高。

ただホテルによっては駅から離れていたりロビーが上層階にあったりして、徒歩アクセスが難しいところもある。素直にタクシーを使った方がいいかもしれない。

Tier2
ブランド品
格好いいが高いしなぁ、と思ってたブランド品も買ってみた。 いい物持ってるな、という満足感がいい。店舗で購入するときの接客体験もいい。
使い込むともっと楽しくなる気がするが、まだTier2。


投げ銭
スーパーチャットなどの投げ銭をしたことなかったのでTwitchのビッツを買って何度か投げていた。素直に応援したい気持ちと反応してもらえて嬉しい気持ちが混じってなかなかいい。
リアルタイムに視聴してないと投げれないのでハードルは高い。JST深夜帯に配信してくれる人が好き。
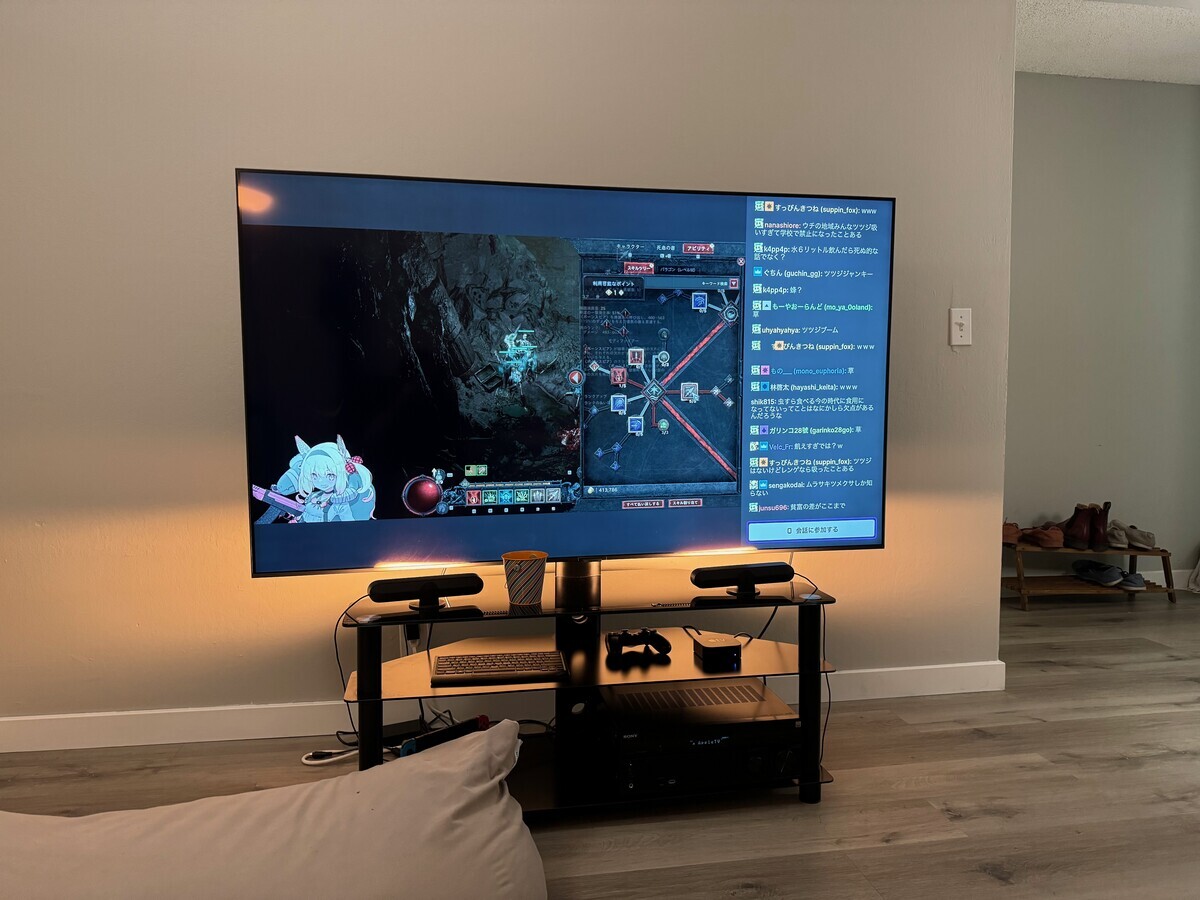
Tier3
ゲーム
Windows機を新調したのでいくつかゲームも買った。Windows11のセキュリティ機能と相性が悪いのか、プレイできないゲームも多かった。
Windowsなら問題なくゲームできると思っていたが、それはもう過去の話なのだろう。

オーダーメイド天板・キーキャップ
天板とキーキャップをオーダーメイドした。サービス自体には不満がないが、こちらの発注内容に起因する不満がいくつかある。今後改善したい。


*1:メンタル的なものかもしれない
ノベルゲーム移植の歴史
この記事はインターネット老人会 Advent Calendar 2023 - Adventarへの飛び込み参加である。
これは数年前に書き溜めていたテキストであり、一部調べきれていない箇所がある。また不正確な記述も混じっていると思う。
この内容を話すためのイベントが2000年ごろのインターネットを懐かしむ会(ハッシュタグ: #インターネット老人会)であり、「インターネット老人会」というミームを生み出す一助となったと自負している。*1
概要
1990年代後半、PCの画像表現・能力の向上と低価格化により、PCユーザが増加した。 その変化の中で、「ToHeart」「Kanon」などといった成人向けノベルゲームが大ヒットし、ジャンルとして定着した。

大多数のノベルゲームはWindowsのみを動作プラットフォームとしていた。そのため、BSD/Linux等の非WindowsOSで、そのようなノベルゲームをプレイできない。 また、当時の携帯端末はPalmOS/WindowsCE等の携帯端末用のOSで動いていたため、同様にノベルゲームをプレイできない。
ノベルゲームはの主要な要素は画像、音楽、テキストを表示するだけで成立し、シビアなタイミングが要求する他種類のゲームと比較すると技術的難易度が低い。そのため、一部ユーザにより、他OSへの移植が盛んに行なわれた。
本稿では1990年代末期から2000年代初頭にかけて行なわれた、ノベルゲームの他OSへの移植について述べる。ただし、すでに多くの情報が散逸しており、一部不正確な記述が混じることとなる。
移植のアプローチについて
非Windows機でノベルゲームをプレイできるようにする手法はいくつか存在している。 以下に詳細をあげるが、本稿ではこれらを総称して移植と表記する。
互換動作環境
開発コストを下げるため、ノベルゲームは既存のノベルゲームエンジン(以下エンジン)上で動作するように開発されることが多い。 またそのエンジンは、メーカごとで共通化されていることが多い。
そこで、そのエンジンの動作を解析し、その動作を再現するプログラムを開発することで、別環境にノベルゲームをプレイすることができる。 本稿ではこのプログラムを互換動作環境と表記する。
本手法の利点として
- 一度、互換動作環境を開発すれば同一をエンジンを用いる別のノベルゲームもプレイ可能
- 元のゲームエンジンに忠実に開発すれば、プレイ感も維持できる
という点があげられる。
反面、大半のゲームエンジンは仕様が公開されていないため内部の動作の解析作業が必要となる上、互換動作環境の開発も必要となる。そのため、作業量が多くなりがちである。
変換ツール
互換動作環境を開発する方法では独自のプログラムを開発していた。しかし、NScripter/吉里吉里といった仕様が公開されたオープンなエンジンがいくつか存在している。
そこで、元のゲームのテキスト・画像・音楽等のデータを抜き出し、別のエンジン上で動作するよう変換を行なうことで、別環境でノベルゲームをプレイできるようになる。 本稿ではこの変換を行なうツールのことを変換ツールと表記する。
移植先のプログラムを作る必要がないため、データの抽出部分にのみ注力することができ、移植のための作業量を軽減できる。ただし、移植先のエンジンの表現力の制約をそのまま受けるため、必ずしも元のゲームの挙動を再現できるわけではない。
移植対象となったOS・機器
移植対象となった主なOS・機器について挙げる。 本稿は移植対象のOS・機器に対する解説が主ではないため、簡単な導入に留める。
PC-UNIX
当初、UNIXは高速な汎用機上で動作するよう設計・開発された。しかし、90年代にはPCの処理性能が向上し、いくつかの実装が登場した。また、これらはPC-UNIXと呼ばれた。
UNIXではGUIはX Window System(以下 X Window)というOSとは独立したコンポーネントにて実現されている。そのため、ノベルゲームを移植する際にはX Windowへの移植が主に行なわれていた。
またOSとは独立しているため、1つの互換動作環境は複数のOSをサポートすることが多い。例えば、Leafゲームの互換動作環境であるXLVNSは以下のOSをサポートする。
携帯端末向けOS
携帯情報端末(PDA)と呼ばれる小型の携帯端末が各社より販売されていた。当初はスケジュール、ToDoといったものが主であったが、2000年ごろには画像表示、音楽再生等のマルチメディア機能を搭載するようになった。
ノートパソコンと比較すると機能は限定的であるものの、持ち運びが容易であるため、常にノベルゲームをプレイしたい層によって移植が行なわれた。
PDA用OSは複数存在しており、主に以下のものが移植対処となった。
ゲームボーイ/ゲームボーイアドバンス
本来、ゲームボーイ/ゲームボーイアドバンス等の携帯ゲーム機のプログラム開発には専用の開発キットが必要である。またそのような開発キットはゲームの開発メーカより正規のライセンス許諾を受けなければ入手できない。
しかし、ユーザによる解析およびマジコンと呼ばれる非公式なプログラムも起動できる装置の登場により、自作ゲームを起動させることが可能となった。
これを利用し、ノベルゲームの携帯ゲーム機への移植も行なわれていた。

権利会社との関係性について
ノベルゲームの解析は利用許諾に抵触しかねない行為だが、メーカーとの関係は概ね良好であった。 xkanon/xakane/xvns等は販売会社に許可をとった上で配布されていた。また、鎮花祭というゲームでは互換環境へのリンクが貼られていた。

System3.5互換動作環境
アリスソフトは1980年代のアダルトゲーム創生期から存在するゲームブランドの1つであり、今なお大手として存在し続けている。後述するゲーム性よりもシナリオを重視したノベルゲームと異なり、アリスソフトはゲーム性に富んだ戦略SLG、RPGなどといったものも多数リリースしている。

Windows95発売以降のアリスソフトのゲームは、基本的にSystem3.5という独自のゲームエンジン上で動作するよう開発されている。 さらに、このSystem3.5の仕様は公開されていたため、他の環境への移植が盛んに行なわれた。
ただ、そういった開発はすべて2000年以前に主な開発が行なわれおり、ほぼすべてのサイトが消失してしまったため、あまり詳細な情報は残っていない。
System3.5 for X
System3.5 for X(別名: XSystem 3.5)は、X Window Systemを用いたSystem3.5互換動作環境である。
- 主な動作環境: Linux(i386), FreeBSD, DigitalUnix
- 開発者: Chikama(wren)氏
- 開発時期: 1997-2000年ごろ
- 配布サイト: http://8ne.sakura.ne.jp:20008/chika/unitbase/xsys35/ (消滅)
このSystem3.5 for Xの存在が後の互換動作環境に大きな影響を与えることのなる。特にXにおける全画面表示のための処理部分は、多くの互換動作環境の開発において、参考にされた。
Debian/Ubuntuのレポジトリにも格納されているため、現時点でもインストール・ソースコードの入手が可能である。

SD35B
SD35Bは、BeOS上のSystem3.5/3.6の互換動作環境である。
- 主な動作環境: BeOS
- 開発者: Atsushi Mizuguchi氏
- 開発時期: 1999年ごろ
- 配布サイト: http://www.sirius.gr.jp/~mizuguch/beos.html
SD35C
SD35CはSD35Bを元とした、PocketPC上のSystem3.5/3.6互換動作環境である。
- 主な動作環境: SD35C
- 開発者: yossy
- 開発時期: 2001年-2004年ごろ
- 配布サイト: http://web.archive.org/web/20011214025703/http://isweb27.infoseek.co.jp/computer/yossoy/sd35c/
これは先行する互換動作環境に強い影響を受けており * SD35Bのシナリオデコーダ部分 * System3.5 for X Window Systemの処理の一部 * わっふる for PocketPC(後述)の音楽処理ルーチン を参考に開発されている。
その他
System3.5以前のアリスソフトのゲームは、System3(PC98)もしくはN88-BASIC(PC88/PC98)で動作するようになっていた。これらのソフトウェアをSystem3/System3.5に移植し、Windows環境環境でプレイできるように変換するツールがいくつか存在している。
詳細が不明なので列挙に留める。
- DOS/V 移植キット
- PC98のSystem3をDOS/VのSystem3に移植する
- 開発はwren氏。System3.5 for Xのwren氏と同一か?
- N88BASIC→MS-DOS移植キット
- N88BASICで開発されていたゲームをSystem3に移植する。
- 1992年から1997ごろにかけてRyu1氏によって開発。
- N88BASIC→System 3.5
- 1997年ごろUNITBASE ひろひろ氏によって開発。
- System3.6移植
- System3をSystem3.6に移植する。
- 1999年ごろUNITBASE TOTO氏によって開発。
また移植以外にもSystem3を直接Xで実行できるようにた互換動作環境も存在する。
- Xsys3
- System3をXに移植してる。
- 後程、何度か登場する古川氏によって1998年ごろに開発されている。
Leaf/LVNS
Leafは1996年にビジュアルノベルシリーズ(Leaf Visual Novel Series; LVNS)として『雫』、『痕』をリリースし異色の作風でゲームマニアに存在をアピール、口コミやパソコン通信、同人誌などで人気がでる。1997年にビジュアルノベルシリーズの第3弾として発売された『ToHeart』のヒットで、成人向けゲーム業界のトップブランドとしての地位を確立した。
仕様は公開されていないものの、「雫」「痕」「ToHeart」はほぼ同一のエンジンで動作している。そのため、それらの互換動作環境もしくは移植ツールが開発された。
痕メッセージ作成ツール
詳細不明。「秋田氏」によって開発されており、SCNファイルの解析を含んでいた模様。
(TODO: もうちょっと詳細を調べれないか)
Lfview
「雫」「痕」「To Heart」に含まれる画像データをデコードするプログラム。
TF氏によって1997年から2001年ごろまで開発されていた。最終的に「さおりんといっしょ!!」「初音のないしょ!!」「White Album」「こみっくパーティ」などの画像もデコードできるようになった。
PVNS
PVNSはPalm上の「雫」「痕」「ToHeart」互換動作環境である。
yossy氏によって開発されていた。開発時期は不明だが少なくとも1999年には開発がスタートしていた模様。「痕メッセージ作成ツール」「Lfview」を参考にし、開発された。
後にyossy氏はSEVENという互換動作環境を開発している。
XLVNS
XVNSはX11上の「雫」「痕」「ToHeart」互換動作環境である。
ごう氏によって1999年末ごろから開発されていた。Palm上の互換動作環境であるPVNSをベースに、XSystem3.5のサウンド処理ルーチンなどを取り込んで開発された。
(TODO: 日記から開発時のエピソードをサルベージしたい)
このXLVNSは、その後のノベルゲームの互換動作環境において大きな影響を与え、様々な互換動作環境にアイデア・コードが引き継がれていくことなる。また、開発者であるごう氏も、XLVNSの開発だけに留まらず、denpa.org上でCVSやMLのホスティングを行ない、互換環境開発において中心的な役割を担っていった。
(TODO: ごう氏はBSDの日本環境での利用において、第一人者。また今もゲーム業界にいるらしい。)
ZVNS
ZVNSはZaurus上の「雫」「痕」「ToHeart」の互換動作環境である。
S.TAKe氏によって2000年から2001年ごろまで開発されていた。xlvnsがベースとなっている。また、yatsushi@ss.titech.ac.jpの解析結果が参考にされてらしいが、詳細不明。
http://web.archive.org/web/20011214103741/http://kisyuya.on.cg/zvns/
MGLVNS
MGL2はハンドヘルドPCなどのリソースの少ないマシンでノベルゲームを動作させるためのウインドウマネージャである。
MGLVNSはMGL2上の「雫」「痕」「ToHeart」の互換動作環境である。
2001年ごろTF氏によって開発開発されていた。XLVSをベースに、鎮花祭 for MGLのコードを取り込んで開発された。ソースコードは後にXLVNSに取り込まれることとなる。
http://web.archive.org/web/20011201212219/http://hoshina.denpa.org/mglvns/
Kanon/Air
Keyは株式会社VisualArt’sのブランドの一つであり、そのゲームの開発にはAVG32という共通のエンジンが用いられていた。そのため、開発結果は流用され、後続のAir,Clanadの移植、また別ブランドで開発されたゲームの移植へと繋っていく。
xkanon
xkanonはX11上のAVG32の互換動作環境である。
Kanonを動作させることを目的に開発がスタートしたが、最終的にはさまざまなゲームも動作するよう拡張された。
- AIR
- さよならを教えて
- 好き好き大好き
- フロレアール 〜 好き好き大好き
- Sense off
- ススキノハラの約束デモ
- それは舞い散る桜のように
- SHUFFLE!
- 恋愛Chu! デモ
- 未来にキスを
- 雛ちゃんの唄声
2000年〜2001年ごろONE for MSXの計画に着想を得たjagarl氏によって開発された。xlvnsのX部分、Xsystem3.5のサウンド部分を流用している。
READMEに作者の住所が記述されており、歴史を感じるものとなっている。
問題などが見つかったら、以下のメールアドレスまで連絡ください。 また、 xvn-devel メーリングリストでもサポートを行います。 詳しくは http://www.creator.club.ne.jp/~jagarl/xvn-devel.html にメーリングリストの解説があります。
作者連絡先 : mail address jagarl@creator.club.ne.jp 住所 茨城県つくば市梅園2-33 学園オアシス203号 TEL 070-6527-8081
Kanon/Air音声化パッチ
KanonはAVG32上で動作していたため、Kanonでは用いられていないもののセリフに併せてボイスを再生する機能があった。
また、当時販売されていたDreamCast版のKanon全年齢版が発売されており、そちらには声優によるボイスがつけれれていた。
さらに、DCゲームからのデータ吸い出しについてはすでに技術が確立していた。メディアが特殊なため、PC用のドライブでは読み込めない。DCに特殊なソフトウェアを読み込ませ、ネットワーク経由でデータを吸い出す。
xkanonのスクリプト解析結果、DCからのデータ吸い出し等を統合し、kanonの音声化パッチが作られ配布されていた。 のちに、同様の手法でAirの音声化パッチ、PS2版Kanonのボイスデータも利用できるAVG32等が開発されている。
(TODO: 開発時期不明)
わっふる(Mac版)
わっふるは各種プラットフォームにおけるkenjo氏によって開発されたAVG32の互換動作環境である。対象とするアプリケーションはxkanonと重複しているが、xkanonがXでの動作であったのに対し、わっふるはMac/Zaurus/WindowsCE等で動作していた。
kenjo氏は自身の日記に、開発の動機を以下のように記している。
プラットフォームによる違いもあるかもしれませんが、Macの場合、既に十分に実用に耐え得るWindowsエミュレータが存在しているので、敢 えてネイティブに移植することにどれだけの意味があるのか、というのが根本的にはあるわけです。若しくはエミュレータ上で動かないものを「やっぱりMac でもXXの笑顔を見たい!」というのでネイティブ移植するとか。
(中略)
なんと云うか、私の場合、根本的に「動かすこと」自体よりも、「動くまでの過程」の方が面白いんですね、きっと。エミュレータ作成の動機もそうでしたけど、分からなかった部分が分かったときの、「謎は解けた! 犯人はヲレだ!!」の為に作っている、という部分がかなり大きいです。そういう意味では、「他プラットフォームへの『移植の』動機」とは厳密には云えないかもしれない。
オリジナルのわっふるはMacOS上のAVG32の互換動作環境である。2001年ごろわっふる for Zaurusと並行して開発されていた。 なお、ここではUNIX化されたMacOS X以前のMacである。
http://web.archive.org/web/20011129000639/http://waffle.bunkasha.co.jp/
わっふる for Zaurus
わっふる for Zaurusもしくはざう版はZaurusu上のAVG32互換動作環境である。前述のようにわっふる(Mac版)と同時並行に、kenjo氏によって開発されていた。 http://web.archive.org/web/20020607221954/http://waffle.bunkasha.co.jp/zau/
わっふる for PocketPC
わっふる for PocketPCはWindowsCE上のAVG32互換動作環境である。2001年ごろにわっふる for Zaurusをもとに古川氏によって開発され、Zaurusu版にソースコードがマージされた。
http://web.archive.org/web/20020607221954/http://waffle.bunkasha.co.jp/zau/
わっふる for PostPet
詳細不明。WindowsCEが動作するPostPet専用端末が販売されていたので、それ向けの移植と思われる。
くろこげ
わっふる(Mac版)はMacOS X以前のMacで動作していたが、それをCarbonAPIを用いてMacOS Xに移植したのが、くろこげである。2001年ごろketa氏/白石氏によって開発されていた。
http://web.archive.org/web/20020402234940/http://homepage.mac.com/keta_/kurokoge.html
ONE
ONE〜輝く季節に〜は、Tacticsによって開発されたノベルゲームである。
時代的にはxkanonよりも前だが、移植時期は後になる。
「田尻さん」「モルシさん」「にゃりんさん」よる解析結果 「田尻さん」「モルシさん」「にゃりんさん」によってONEの解析がされそれがベースになっているが、詳細不明。 (TODO: サルベージする)
xakane
nao氏によって開発されたONEの互換実行環境。2000年~2002年ごろに開発されていた。 xlvnsに影響を受けて開発が開始されており、コードとしてはxkanonから一部コードが参考にされている。
名前の由来は以下のように記述されている。
プログラム名の"xakane"は、「えっくすあかね」と読みます。実行ファイル名を 決める時、"x"という文字を含みかつ"one"という文字を含む良い名前が思い浮か ばなかったので、独断と偏見により"akane"を採用しました。
名言されていないが登場キャラクターである茜に由来すると思われる。
また、コード自体はgithubにコピーされ、今も内容を確認できる。
https://github.com/nonakap/xakane-gtkmm2
あかね for Pcoket PC
古川市によって開発されたPocketPC上のONEの互換実行環境。2001年ごろ古川市によって開発されていたが、詳細は不明。
名前からしてxkananeをベースにPocketPC環境に移植されたと思われる。
http://web.archive.org/web/20011204001231/http://watasimo.pyon.org/akaneppc.html
あかね for zau
kenjoはZaurusu上のONEの互換実行環境。2001年ごろkenjo氏によって開発されていた。xakaneのコードを元に開発されている。
名前の由来は
「xakane」に合わせると「zakane」なのですが、「ざかね」だとなんかかっこ悪いので ^^;、名称は素直に(?)「あかね(for Zau)」にしました。
とのこと。
http://web.archive.org/web/20020607221954/http://waffle.bunkasha.co.jp/zau/
Studio Air
StudioAirは伝奇系ノベルゲームを得意とする会社であり、1999年に鎮花祭を発売した。
StudioAirは互換動作環境開発について比較的寛容だったらしく、公式ページから各互換動作環境へのリンクが貼られている。

鎮花祭 for X(xhana)
X上の鎮花祭の互換実行環境。TF氏によって2000年ごろに開発された。 xlvnsを参考に開発されている。
http://web.archive.org/web/20011211213536/http://hoshina.denpa.org/hanashizume/xhana.html
鎮花祭 for Palm(phana)
Palm上の鎮花祭の互換実行環境。鎮花祭 for Xと同時並行する形で、2000年ごろTF氏によって開発された。 鎮花祭 for Xがxlvnsを参考にしたのと同様に、こちらはpvnsを参考に開発されている。
http://web.archive.org/web/20011021231626/http://hoshina.denpa.org/hanashizume/phana.html
鎮花祭 for PocketPC(cehana)
PocketPC上の鎮花祭の互換実行環境。pvns等を開発したyossy氏によって2002年ごろに開発されていた。 鎮花祭 for Xがベースとなっている。
http://web.archive.org/web/20020203025949/http://isweb27.infoseek.co.jp/computer/yossoy/cehana/
鎮花祭 for MGL2
MGL2はUnix系OS(BSD, LINUX)がインストールされたPDA上で動作することを主目的とした軽量なウインドウマネージャである。 主にNECより発売されていたモバイルギアがターゲットさらていた。
鎮花祭 for MGL2はそのMGL2上の互換実行環境である。くがわた氏によって、2002年ごろ開発されていた。 鎮花祭 for Xがベースとなっている。
http://web.archive.org/web/20020204131046/http://www2.osk.3web.ne.jp/~kgt/strage_room.html
鎮花祭 for ICRUISE
ICRUISEはZaurus MI-EX1 と Zaurus MI-TR1 の総称であり、当時としては大きいVGAサイズの液晶を搭載していた。 (TODO: もうちょっと補足してもよさそう; http://hp.vector.co.jp/authors/VA004474/zaurus/zrep37.html)
そのICRUISE上の互換動作環境が鎮花祭 for ICRUISEである。後に家族計画 for Xを開発する「のなか/埜中公博」氏によって、2001年ごろに開発された。
http://web.archive.org/web/20010804165837/http://www.asahi-net.or.jp/~aw9k-nnk/z/zhana.html
その他
NScripter
汎用的に動作するので、これに変換するやつが結構あった。
- 夢守猫
- http://web.archive.org/web/20011214000049/http://www.i-chubu.ne.jp/~reina/yumeneko.html
- NScripterのZaurus実装
- 2001年ごろ水原氏によって開発されていた。
- zauのコードが参考になっているがベースになっているわけではないらしい。
- GNScripter
- http://web.archive.org/web/20011024163517/http://watasimo.pyon.org/index.html
- 2001年ごろ古川氏によって開発されていた。
- 詳細不明。
- ONScripter
- http://web.archive.org/web/20030520202221/http://abe.nwr.jp/onscripter/
- Linux環境での動作を目的として開発がスタートしたっぽい。
携帯ゲーム機への移植
インテル帽子屋(後に帽子屋インサイドに改名)によって、ゲームボーイ等への携帯ゲーム機へのノベルゲームの移植が行われた。 インテル帽子屋は1994年に着せ替えソフト「KISS」のデータ集を扱う個人サークルとして設立された。その後、TinyONE(詳細不明; 携帯ゲーム機へのONEの移植か?) に影響を受け、ゲームボーイへのノベルゲーム移植を開始する。

広い意味ではこれも互換動作環境の開発といえるが、前述した各互換動作環境との技術的なつながりは発見できなかった。
http://web.archive.org/web/20061210004611/http://www.inside-cap.com/history/intelcap_history.htm
ゲームボーイもしくはゲームボーイアドバンス上で動作するエンジンMiNAGI/MiNAGI for ADVANCEを開発し、そのエンジンに向けて各種ノベルゲームを変換することで、移植を実現する。
また、他の互換環境と異なり、ゲーム本体を含んだROMイメージを作成するという性質上、不正コピーを防ぐための仕組みをいくつか導入してしている。詳細は公開されてないが、ROMイメージを作成したマシンと異なるマシン上のエミュレータでは実行できない仕組みが取り入れられいた。
http://web.archive.org/web/20061220083528/http://www.inside-cap.com/techs/index.htm http://web.archive.org/web/20070111104700/http://www.inside-cap.com/techs/security/index.htm
最終的に以下のノベルゲームが移植された。
- ひぐらしのなく頃に
- CROSS†CHANGE
- はじめてのおるすばん
- AIR Pocket
- 月姫
- 君が望む永遠
HP200LX
- HP200LX用: 痕、終末の過ごし方
- 2000年〜2001年ごろ大道氏によって開発されていた。
- KanonLX
- http://web.archive.org/web/20011109092730/http://homepage1.nifty.com/kibojin/keylx/index.html
- 2001年ごろ跂望人/鈴木達哉によって開発されていた。
今後の課題
未調査リスト
- BeOS
- Windowsの実行形式であるPE(COFF)を解釈するライブラリを作って、EXE/DLLを メモリにマップ。Windowsでは、Win32APIは直接呼び出されずに、 外部参照のDLL内で解決されることを利用して、KERNEL32.DLL/USER32.DLL/etc... 等のDLL相当のものをBeOS nativeのAPIを使って再実装。 あとはnativeに動きますんで、動作速度も快適ですし、 CPUがDualなら当然Dualで動きます。
- http://www.toyoshima-house.net/classic/beos/index.html
- X11用ルーキーズ、ラブ・エスカレータ
- http://web.archive.org/web/20011214125235/http://watasimo.pyon.org/index.html
- 1998年5月20日〜1998年9月2日の間、古川氏によって海月製作所のPC98用ゲームがXに移植されていた。
- 古川市は後ほどわっふる for PocketPCl/あかね for PocketPC/ザウルス用AVG32の開発を行なっている。
- ONE for MSX
- http://web.archive.org/web/20011211202840/http://www.akari-house.net/one-msx/
- 2000年ごろ、レジャーソフトの黒田氏によって制作が計画されていたが、頓挫した模様。
- ゆめみっくす、だいなあいらん対応アニメーションローダ
- http://web.archive.org/web/20011109073421/http://hp.vector.co.jp/authors/VA004239/it_tool.htm
- 1997年から1998年ごろまでAOI氏によって開発されていた。
- メガCDやサターンで発売されていた”インタラクティブコミック”を各種PCで動作させるためのコンバータ
- Palm MOON/ONE/Kanon
- ONE/とらいあんぐるハート/月姫
- http://web.archive.org/web/20011031000317/http://hp.vector.co.jp/authors/VA003720/lpproj/os2/one2.htm
- OS/2は互換性が強いので互換レイヤーっぽいやつ。
- wineとかに似てるのでは?
- ONE
*1:改めて見るとさしてインターネットと関係ない
ハードウェアDvorakキーボード
要約
WASD KeyboardsとKeychronを組み合せてDvorakキーボードを作った。

動機
昔からDvorak配列を愛用している。非QWERTY配列の中では比較的メジャーで、各種ソフトウェアが対応してることが多い点が気にいってる。
しかし、たまにうまく動かないケースがある。
- VM内ではQWERTY配列に戻る
- マウスについてる補助ボタンまでリマップされて、設定画面と実際の挙動に齟齬がでる
- MS IMEが対応していない。*1
なのでソフトウェア側の対応が不要なハードウェアDvorakキーボードが欲しかった。
キーボード本体
QMK Firmwareのおかげでキー配列がカスタムできるキーボードが増えており、大変ありがたい。特に入手しやすいKeychronシリーズが好き。
テンキーが欲しかったのでKeychron Q6 Proにした。キースイッチは、今手元にもってないGateronの青にしたが、さほどこだわりはない。

キーキャップ
キーキャップには様々な傾きがありそれぞれプロファイルと呼ばれている。これ以外にも独自プロファイルがいくつかあり、KeychronはKSAを推している。

しかし、WASD keyboardの印刷サービスはCherryプロファイルのみの対応なので、Cherryプロファイルにした。*2
Illustratorでデータを作って入稿した。フォントは好みでFuturaにした。Controlキーの移動やCapslockの廃止などもした。

組み立ての様子


先代
Low profileキーボードならすべてのキー形状が同じなので、それを入れ替えて使っていた。
ホームポジション用の突起はYouTube Keyboard Stickerを使っていた。Amazon.com でもLocator dotという名前で似たものが売っている。

*1:正確には裏口が塞がれたJapanese IME in Dvorak not working - Microsoft Community
*2:キーキャッププリントサービス | 遊舎工房なら他のプロファイルも対応してるらしい。
定期掃除サービス
要約
掃除サービスに満足している。

部屋が汚ない
引っ越し時にあらためて部屋をみたら、ものすごく汚れていた。特にルンバが入れないエリアがひどい。あと水廻り。

改めて考えると段ボールを放置し続けてるのもよくなかった。

汚ないことよりも気づいてなかったことに衝撃を受けて、自力で何とかすることをあきらめた。プロに頼むことにした。
掃除サービスの依頼
Home cleaning serviceとかで調べればでてくる。掃除のみなので、日本での家事代行とは少し違う気がする、使ったことがないので分からない。
AngiやThumbtack が地元の企業や個人との契約を斡旋してくれる(らしい)。試しに見積依頼を出したところからは返信がなかった。
Yelpで探して、Webサイト経由で見積から予約まで完了しそうなinstamaid にした。Heromaid もほぼ同様のサービスを提供していた。

おすすめにしたがって二週間ごとの定期掃除サービスを頼んだ。初回はheavy cleaingにしてほしいと書いてあったが、引越し直後なので省略した。

準備
留守中に掃除してもらうために、こういうやつを買った。Key lock boxと言うらしい。掃除の日は、これに鍵をいれてドアにぶらさげている。

部屋中の照明はSiri経由で制御している。この操作を伝えるのも大変なので、自動で点灯するようにした。

所感
部屋がキレイなのはいい。特に以下の箇所を気にいってる。
- バスタブのカビとかの水廻りがキレイ
- 各部屋においてあるゴミ箱の袋の交換してくれる
- ベッドシーツの交換をしてくれる

人が定期的に来るから片付けよう、っていうきっかけとしても役立っている。床に段ボールを放置しつづけることはなくなった。
快適にすごすためにお金を使うのも悪くない。贅沢をすると罪悪感があるが、多少はいいかもしれない。

🚚最近のアメリカ生活: 引越し
3年住んだら飽きたので引越しをした。
退去通知
契約更新案内をちゃんと読んだら、
- 継続する場合は1日前まででの返信でいい
- 退去する場合は30日前に書類(written form)で通知が必要
と書いてあった。前半だけ読んで油断していた。
確認したら以下の内容を含めたメールを送ればいいらしい。
- 退去日
- 退去後の住所
- 退去理由

引っ越し業社見積もり
引越し業者(Mover)はyelpで探した。
最初は日本語が使える Cross Nation Moving に見積を依頼したが、まったく返信がなかった。
yelpでfast responseとついているとこに依頼したら、即座に返信が返ってきた。Webフォームを入力すると会員用ページのURLが送られてくる。
この段階で引越し保険にも加入できるらしい。やっていないので詳細は知らない。
物件探し
Zillowで探した。

洗濯機が置けてエアコンがついているところにした。なぜかon-site parkingにチェックをいれるとフィルタリングされすぎてしまうので検索条件からは外していた。 駐車場があるのが当たり前でわざわざ入力してないのかもしれない。
だんだんとどこでも一緒な気がしてきてしまって適当に決めた。見学はした。
- Webサイトから物件申し込みをする。
- デポジットの支払いをす
- 書類が送らてくるのでサインして返す。Webサイトでクリックするだけで署名できるが、数が多い。
- 保険の加入と最初の家賃の支払いをする
という流れで申し込めた。
入居日の指定が2週間先までしかできなかった。 引越し日はもう決めてしまってたので、ドキドキしながら待った。 不人気なのか、待ってる間に家賃が下がった。
手続きの順番
それぞれリードタイムが違うので、
- 1ヶ月前: 退去通知
- 1ヶ月前〜2週間前: 引越し業者選び
- 2週間前: 物件決め
という順番でやるのがいい。 実際は全部逆の順番でやって、余計な家賃を払うことになった。次はうまくやる。
ライフライン手続き
電気(PG&E)・インターネット(Comcast)はWebサイトで新住所に移せた。郵便の転送設定もUSPSのサイトでできた。
水道は手続きしてないが、なぜか使えている。
この時、職場に事前の連絡もせず転居してはいけない - 健常者エミュレータ事例集Wikiを見てびっくりした。あわてて調べたけど、事後でよかった。*1
引っ越し
朝からきてどしどし積み込んでくれる。

引越し業者からの案内では、事前にParking permitを取ておいてくれと書いてあったが、特に必要なかった。一応、事前に駐車位置を聞いておいたが、当日は違う場所に停めてた。

見積り時の代金はあくまで予想で、実際はかかった時間に応じた支払いになる。おおむね見積りどおりだったが、追加でチップが必要なことを失念していた。
退去
退去前に事前チェック(Pri Home Inspection)もお願いできる。 ドアのヒンジを壊してたが特に何も言われなかった。どういうメリットがあったのかはよくわからない。
退去日に管理人室(Leasing Office)いったけど閉まってた。しょうがないので部屋の中に鍵を置いてメールした。「確認しました、ありがとう」というメールが返ってきたので、これでよかったらしい。
*1:非健常者に優しい会社なのかもしれない
🪪最近のアメリカ生活: 車
Teslaのアップデート
日本に帰国してる間に、完全自動運転(FSD; 完全ではない)が北米全体に開放されたので楽しみにして帰ってきた。( テスラの完全自動運転ベータ版が北アメリカで提供開始、誰でも200万円払えば利用可能に - GIGAZINE; 購入時に利用権を買ってるので200万円は払ってない)
アップデートしたら周りの車だけでなく、車線も把握するようになってた。
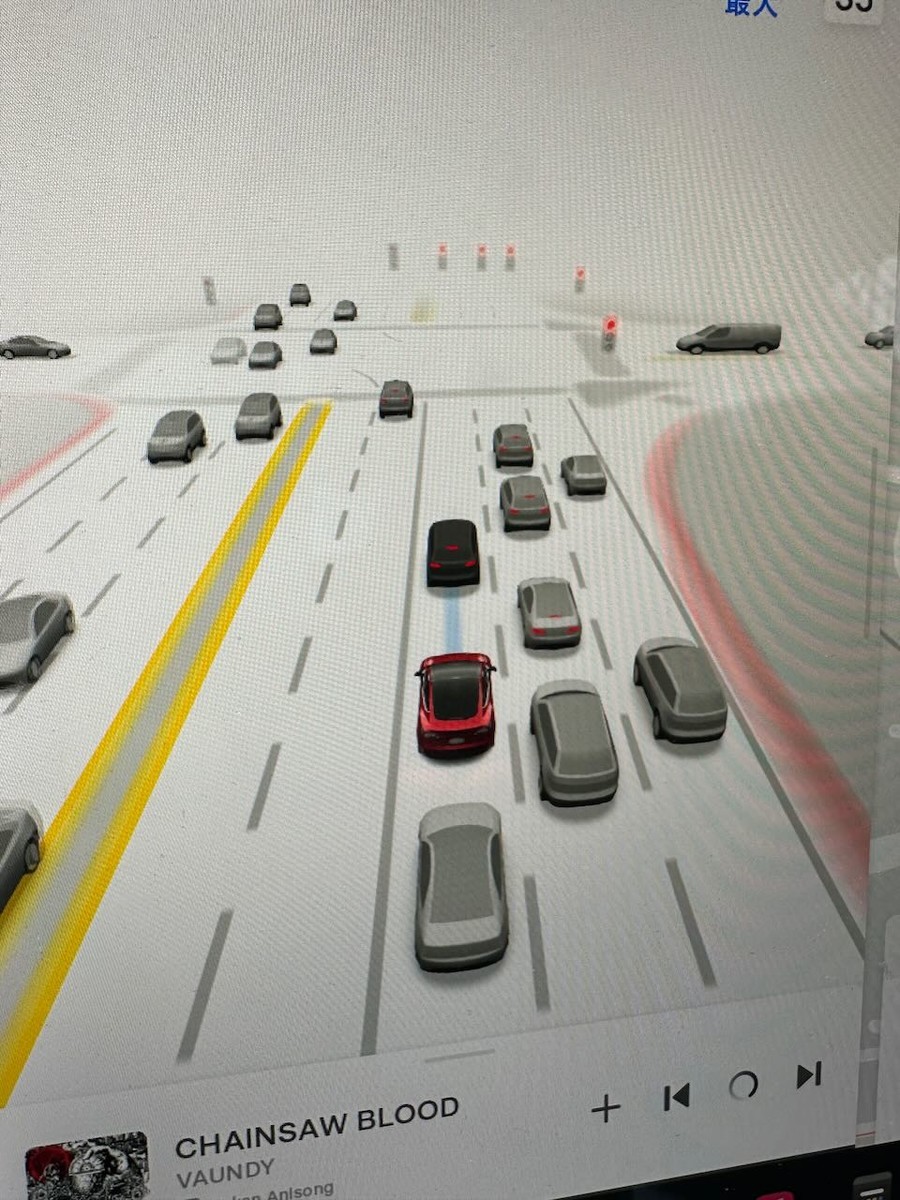 

アップデート前はこれくらいだったので、だいぶ広くなってる。感心する。
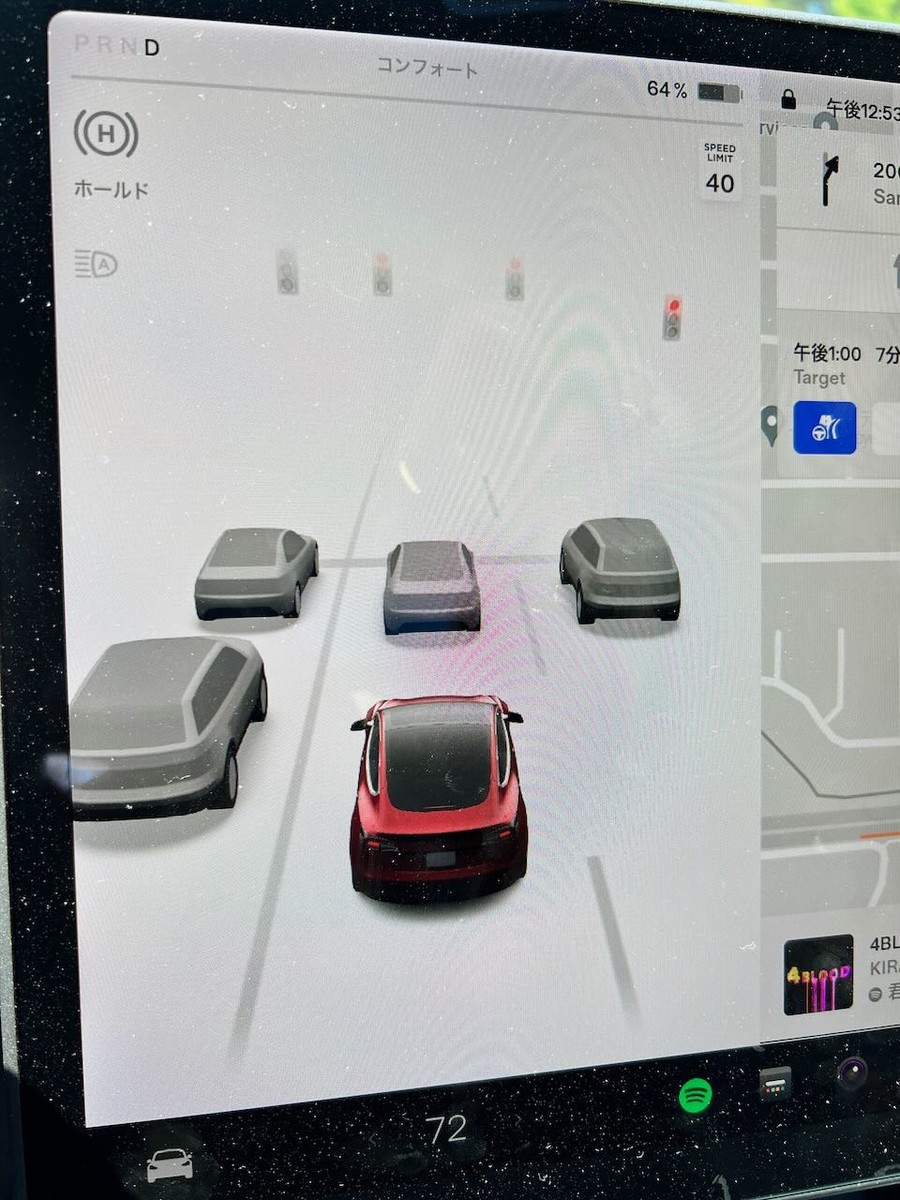
近所のスーパー行くのに使ってみたが、だいたい動いてる。すごい。
ただ加速が激しめでびっくりする。普段は加速をゆっくりにするオプションを使っているが、自動運転だとそれがはずれるのかもしれない。
免許更新
運転免許を更新した。
昨年末に期限切れしていたが、ビザの期限を先に伸ばさないと更新できなかったので先伸ばしになっていた。 早く永住権が欲しい。
DMV(車両管理局)からの通知ではオンラインでの更新を勧められるが、なぜかできなかった。Webサイトに書いてある条件は満してるはずだが..。
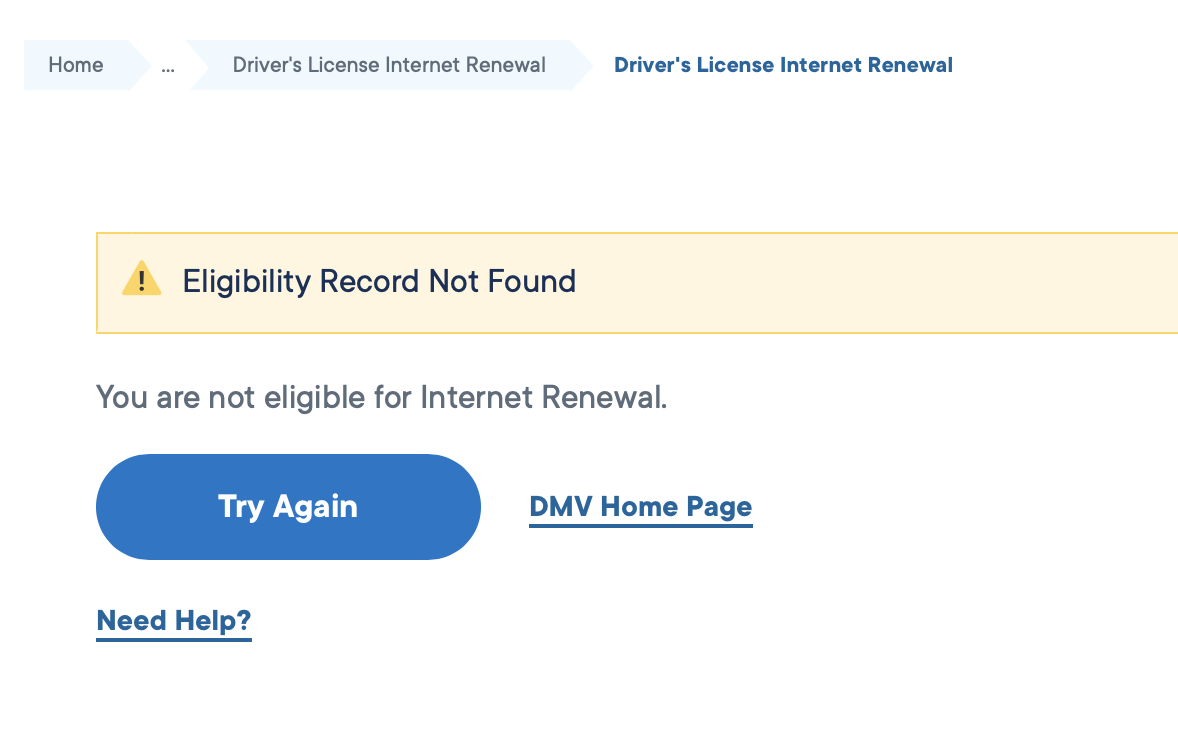
申請
しょうがないので、DMVオフィスに行くことにした。
ただApply Online for a Driver License or ID Cardからオンラインで申請は出せる。ヤードポンド法で身長や体重を聞かれても即答できないので、調べながら書けるオンラインは助かる。髪と目の色を記入するのは多民族国家っぽい。手数料も支払った。
運転講習もオンラインでできた。e-Learning + クイズをやるか、顔をカメラに移しながら試験だけ受けるかを選べたが、いきなり解ける自信がなかったのでe-Learningにした。
途中で中断できるし、いい選択だったと思う。有効期限が一年なのは笑ってしまった。そんなにかける人いるのかな。

DMVオフィス
処理のために一営業日空けてほしいと書いてあったので、Appointments - Service selectionで翌々日の予約を取った。 運転免許の試験の予約を取るのはめちゃくちゃ大変だったが、それ以外は簡単に取れるらしい。
予約してる人の優先レーンが使えてよかったが、書類が足りておらず並び直すことになった。 I-94(出入国書類)が必要なのは把握してたが、必要なページが足りてなかった。
前回は何も持っていかなかったので、ちょっとは成長している。近くのFedexにいって印刷した。二回目なので冷静に対処できる。

そのあと予約を取り直して再度並んだ。「homeworkはやってきたかい?」みたいなことを言われながら再提出した。
その後は窓口に呼ばれるまで待機。30分くらい待った気がする。


窓口では更新内容の確認を確認された上で、視力検査をした。 視力検査は特に器具があるわけでなく、自分で片目を隠して壁に貼ってある文字を答える。眼鏡ごと抑えてたら、眼鏡がズレて見えなくなって焦った。
そのあとは写真撮影をしておしまい。一時的に使えるinterim driver licenseを発行して貰えるので、運転できるようになる。ただ、身分証明書を求められるタイミングでは使えないし、紙の書類なので持ち運ぶのも面倒。
2週間くらいで更新された免許が郵送されてきた。
今月にやること
- 引越したので住所を更新する。
- 車両登録を更新する。
- 内装の掃除をしたい。
RSSリーダー
冬休みにRSSリーダーを書いた。楽しかった。
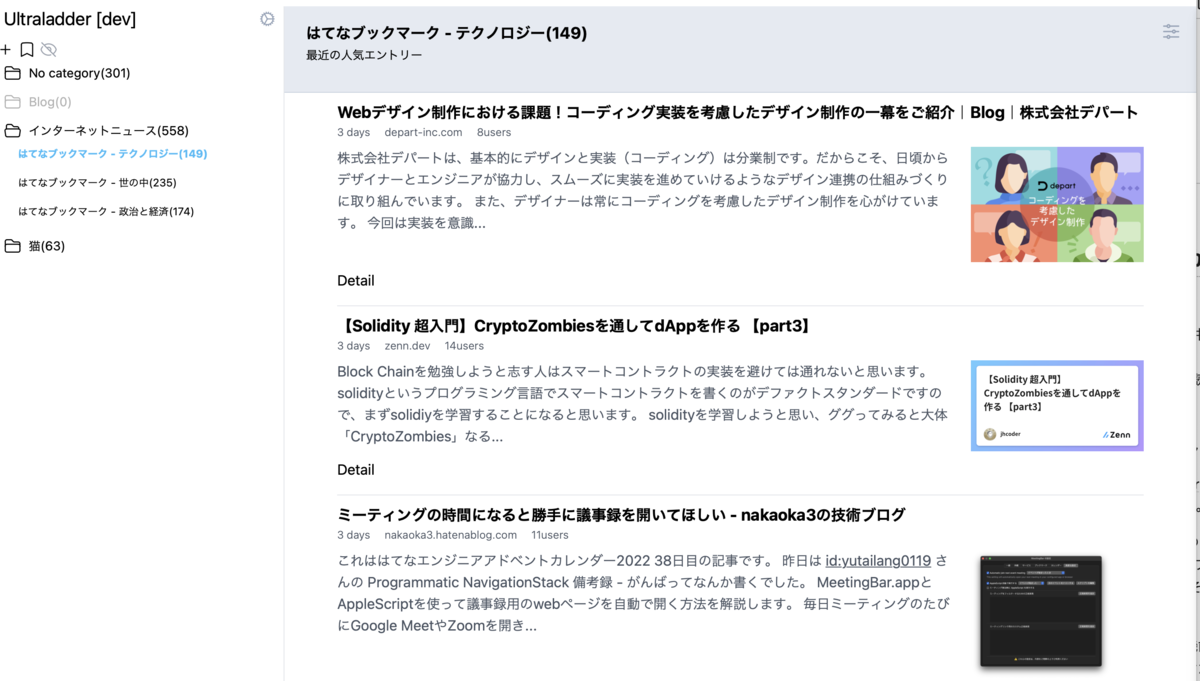
feedlyへの不満
feedlyを使っていたが不満が溜まっていた。
- ネットワークエラーが頻発する。これは日本に一時帰国中で、サーバーから距離があるせいかもしれない。
- 画像が縮小表示されるため、画像主体のRSSフィードが読みづらい。
とはいえ、自作するほどの不満ではない。冬休みで魔が差した。

Ultraladder
インストール不要で複数デバイスからアクセスしたかったので、Webアプリとして作った。これまで使ったRSSリーダーの中ではFastladderが一番気に入っていたので、各所で影響を受けている。jkキーバインドも実装した。
RailsでAPIサーバーとジョブサーバーを、Next.jsでフロントエンドを書いた。AWSにデプロイしようと思ったら思ったより高くなりそうだったので、fly.ioにAPIサーバーを、Vercelにフロントエンドを配備した。
Webサービスとして一般公開するつもりはないので、認証機能などは簡易なものしか付けていない。スケールしそうにない機能もいくつか付けた。
モダンブラウザAPI
最近*1のブラウザの機能は追っていなかったが、改めてみたら便利なAPIがいくつか追加されていた。
scroll-snap-typeでエントリの先頭でスクロールを簡単に止めれるようになった。
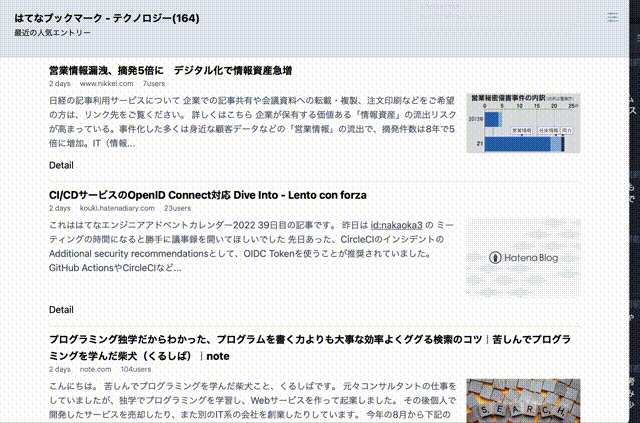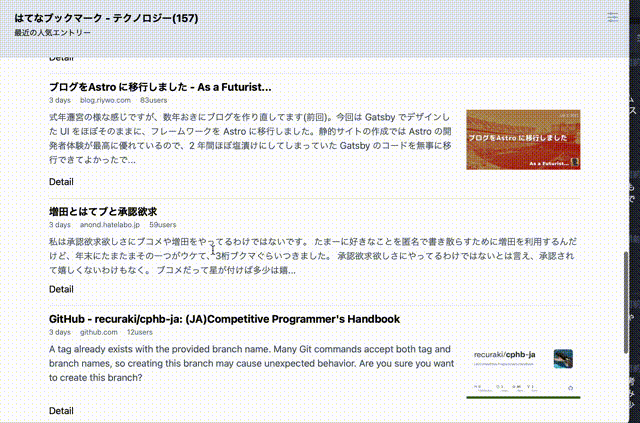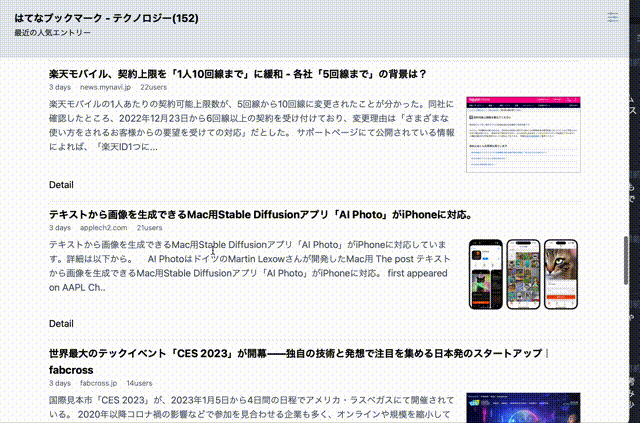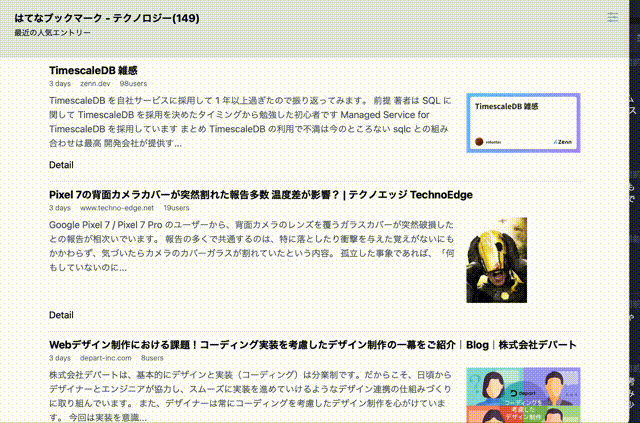
未読から既読への切り替えのためのエントリ表示判定が必要だったが、これもIntersectionObserver APIで簡単に実現できた。
画像用デザイン
画像主体のフィード用のデザインも用意した。
スケールしない機能
同じエントリを複数回見るのが嫌だったので、同じURLはまとめて既読扱いとした。
def mark_as_read item = current_user.items.find(params[:item_id]) read_at = Time.current item.update!(read_at:) # mark same url items as read current_user.items .unread .where(url: item.url) .update(read_at:)
このあたりは購読数に対してスケールしそうにないが、個人用なので遠慮なく実装した。
楽しかった
とても楽しかった。
ほどほどにしてのんびり正月を過ごすつもりだったが、止まらなくなってしまった。 ジョブの実行頻度を間違えてることに気がついて、初詣の帰りにデプロイをやり直したこともある。

YouTubeで音楽をランダム再生しながら深夜までコードを書くのはエキサイティングだった。終盤、メドレーに投入したため、めまぐるしく変わる曲の中でHTMLをいじるのが最高に楽しかった。
思い通りのものが目の前にだんだんと現れてくるの、他に変え難い喜びがある。こういうことがやりたいからプログラミング覚えたのが出発点だったのを思い出した。
*1:2019年